
When Your Automation Makes the Wrong Decision, Who's Responsible?
The Problem
Modern enterprise systems rely on automated remediation (self-healing, scaling, failovers) that operates largely without oversight. When unvalidated, this automation can amplify failures, trigger crash-loops, and extend outages.
The Solution
Safety Automation introduces Control Plane Validation—a structured methodology to prove, not assume, that your automation is safe to trust.
The Methodology
Counterfactual Testing compares system behavior with automation active versus automation suppressed to isolate and measure the actual causal effect of the response.
The Goal
Shift from "Gatekeepers" to "AI Test Architects" by embedding safety validation directly into the development workflow.
The Self-Healing Myth
If your automation can act without proof, it's not resilience — it's hope at machine speed.
The Problem Nobody Talks About
Your database slows down. Kubernetes probes fail. Pods restart. Traffic shifts. Connection storms hit. More pods fail. A small latency issue becomes a full outage. Everything worked as designed — the automation just multiplied the failure.

The Only Test That Matters: The Counterfactual
To know if automation is safe, you need comparison. Run the same failure twice — once with automation ON, once with it OFF.
Now you have proof: "Restarting helped" or "Restarting made this worse." That's not opinion. That's cause and effect.

Governing AI Agents
As we move toward AI-driven remediation, failures will happen in milliseconds. Automation Safety isn't optional — it's the mandatory "Digital Governor" for autonomous agents. In the age of AI, unvalidated autonomy is a death wish.

Regulatory Adherence
Ensure safety integrity and compliance with our robust safety governance solutions. From safety protocols and regulatory standards to audit trails and incident reporting, we provide comprehensive tools to manage and protect your valuable safety assets.
Safety Automation Pillars
AI-powered quality assurance for enterprise systems
Pillar 1: Efficacy
-
Determines if the automated response was the right tool for the failure
-
Detects "Zombie States" where a service appears healthy but cannot process requests

Pillar 2: Stability (The Stability Quotient)
Measures if the system returns to equilibrium or enters a volatile state (thrashing/oscillation) after firing.

Pillar 3: Blast Radius Mapping
-
Visualizes side-effects across the microservices mesh.
-
Confirms if automated actions intended to isolate a component inadvertently export stress to healthy dependencies.

Out of the Box Capabilities
Pod Kill & Restart
Validates whether restart logic clears the fault — or creates a crash-loop
HTTP Latency Injection
Tests whether automation responds correctly to degraded upstream dependencies
HTTP Error Injection
Verifies circuit-breaker and failover behavior under hard dependency failure
Comes pre-wired. No setup. First experiment produces immediate, readable output. Zero dashboard configuration.
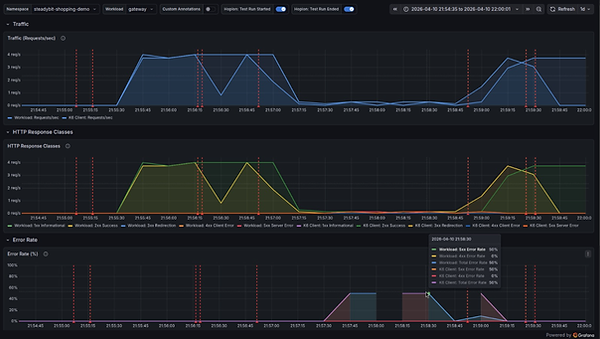
-
Runs in your OpenShift namespace — no cluster-admin required
-
Install it yourself — no SRE or operator needed
-
Development & staging only — structurally can't reach production
-
PDF/A-1b audit reports - ISO archival standard — regulator-ready evidence

We are a RedHat Certified Partner